
Data is crucial for experiment analytics tools, building a dashboard, machine learning models, and software development, among other applications. Real data is sensitive, unavailable, or insufficient. It can pose privacy, security, or availability challenges. Synthetic data fills this gap, and the Faker library is one of the best Python tools for generating fake but realistic data quickly.
In this tutorial, we will show how to generate a synthetic dataset in Python with Faker.
Installing and Importing Faker
First, install the package from your terminal:
pip install faker
Now import it into your Python script or notebook:
from faker import Faker fake = Faker()
- “Faker()” creates a Faker generator, which you can use to create fake data.
Basic Usage: Generate Single Fake Data Points
Let’s see how Faker can generate single pieces of fake information.
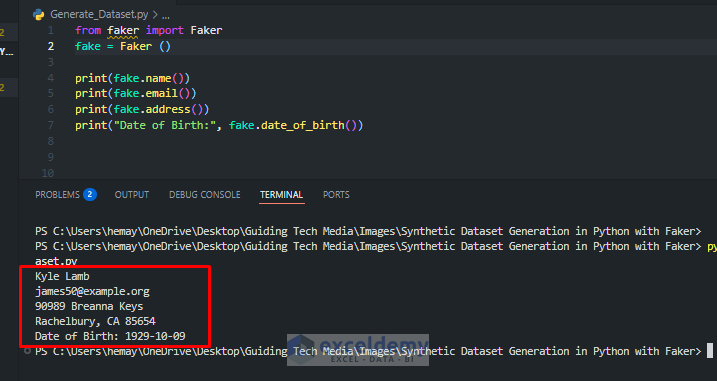
from faker import Faker
fake = Faker ()
print(fake.name())
print(fake.email())
print(fake.address())
print("Date of Birth:", fake.date_of_birth())
Explanation:
- fake.name() returns a random, realistic name.
- fake.address() returns a random street address (can have line breaks).
- fake.email() gives a random email.
- fake.date_of_birth() returns a birth date.
Generating Structured DataFrames
For real projects, you’ll want structured tables with thousands of rows, not just single values. Let’s create a sample dataset of 100 employees for your dashboard.
Python Code:
import pandas as pd
num_samples = 100
data = {
"Name": [fake.name() for _ in range(num_samples)],
"Email": [fake.email() for _ in range(num_samples)],
"Address": [fake.address().replace("\n", ", ") for _ in range(num_samples)],
"Birthdate": [fake.date_of_birth(minimum_age=18, maximum_age=90) for _ in range(num_samples)],
}
df = pd.DataFrame(data)
print(df.head())
Explanation:
- Each column uses a different Faker method.
- It generates 100 values for each column using list comprehensions.
- fake.name(), fake.email(), etc. are called repeatedly for new values.
- .replace(‘\n’, ‘, ‘) turns multi-line addresses into one line.
- fake.date_of_birth(minimum_age=18, maximum_age=90) restricts ages.
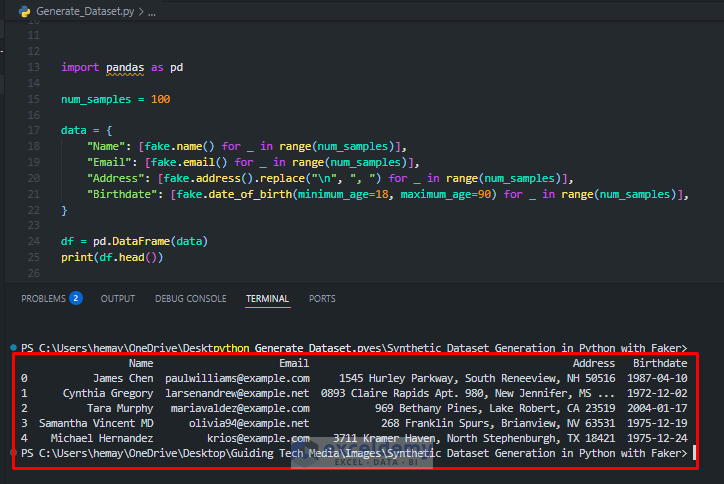
This instantly gives you a realistic-looking HR table, ready for demos and testing.
Customizing the Dataset: More Employee Fields
Let’s add more complexity and expand our HR dataset for more realism, including:
- Employee ID
- Phone
- Department
- Salary
- Start date
Python Code:
def create_employee():
return {
"EmployeeID": fake.unique.random_int(min=1000, max=9999),
"Name": fake.name(),
"Email": fake.company_email(),
"Phone": fake.phone_number(),
"Department": fake.random_element(elements=("HR", "Finance", "IT", "Marketing", "Sales")),
"Salary": round(fake.random_number(digits=5, fix_len=True), -2),
"StartDate": fake.date_between(start_date='-10y', end_date='today')
}
employees = [create_employee() for _ in range(50)]
df_emp = pd.DataFrame(employees)
print(df_emp.head())
Explanation:
- EmployeeID: Unique 4-digit number per person (unique.random_int ensures no duplicates).
- company_email(): Looks like a work address.
- Department: Chosen randomly from a fixed list.
- Salary: 5 digits, rounded to the nearest hundred.
- StartDate: Random date in the past 10 years.
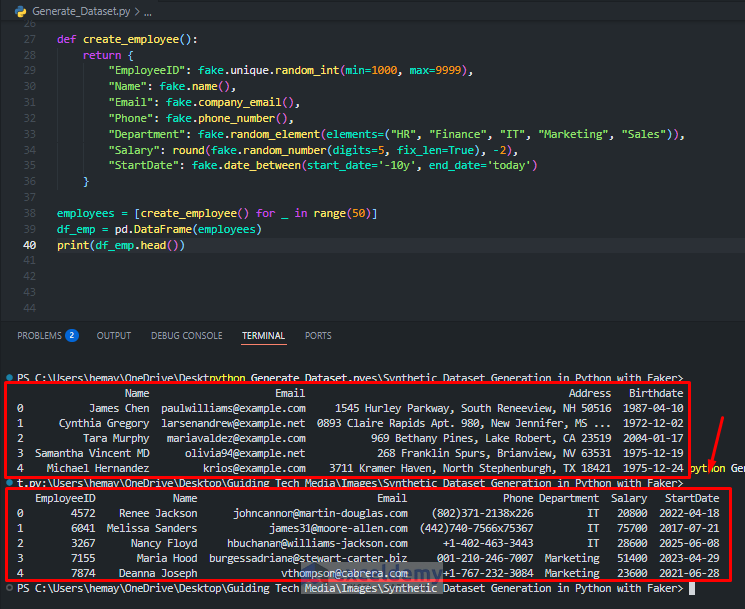
A customized, enriched employee dataset will be great for analytics.
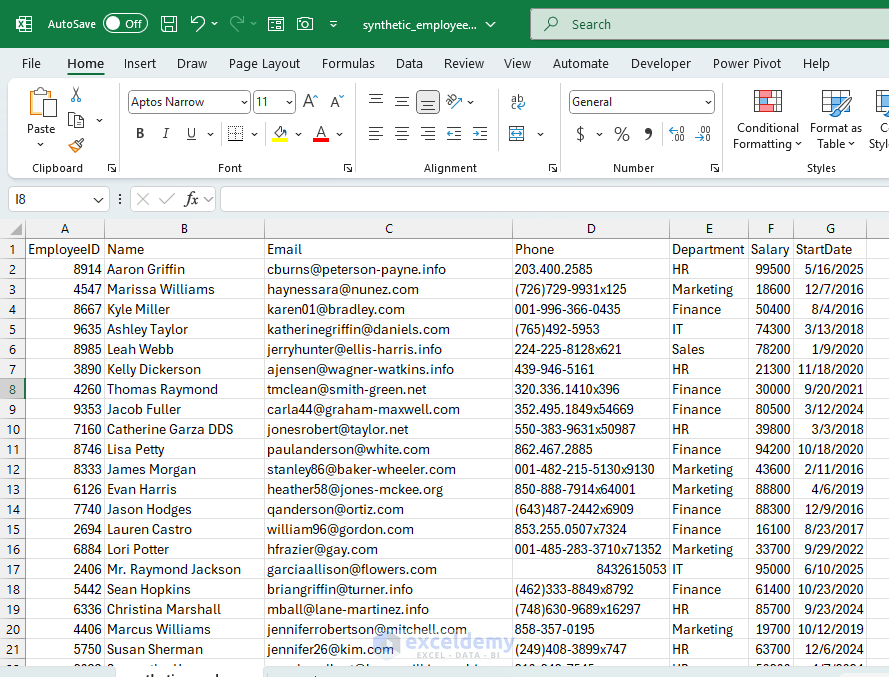
Saving Created Synthetic Data
To use the created synthetic data in other analytics tools, you can export it in CSV.
df_emp.to_csv('synthetic_employees.csv', index=False)
- to_csv saves your DataFrame as a CSV file, readable by almost any tool.

- CSV is universally readable and perfect for demos or testing.
Creating Linked Datasets: Customers and Orders
Let’s say you’re simulating a sales dashboard and need two tables: Customers and Orders. Each order should link to a real (fake!) customer.
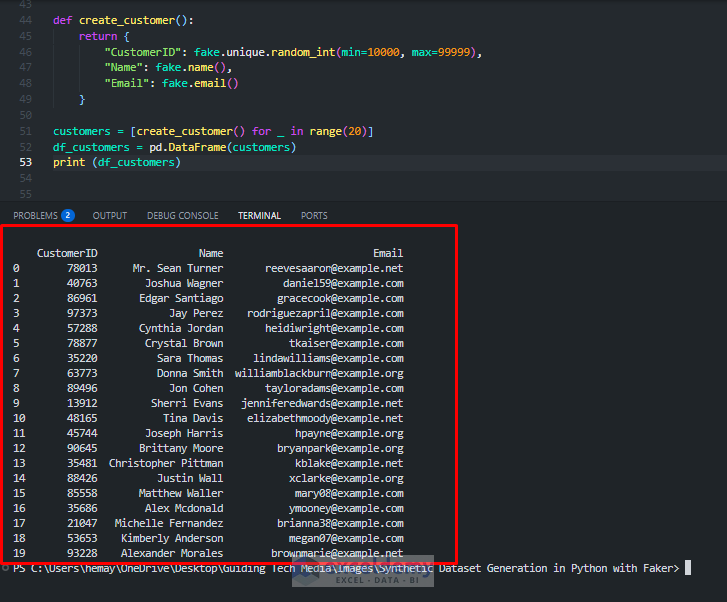
Step 1: Create Customer Data
Python Code:
def create_customer():
return {
"CustomerID": fake.unique.random_int(min=10000, max=99999),
"Name": fake.name(),
"Email": fake.email()
}
customers = [create_customer() for _ in range(20)]
df_customers = pd.DataFrame(customers)
print (df_customers)
- It creates 20 unique customers with their IDs, names, and emails.
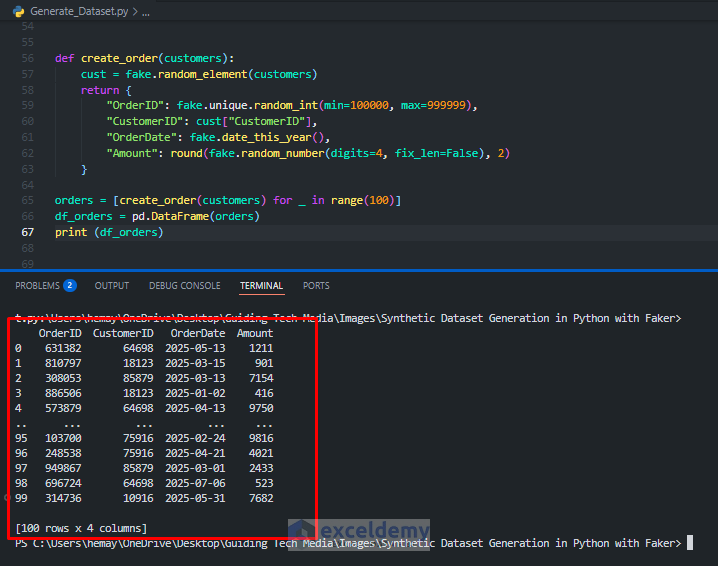
Step 2: Create Orders (linked to Customers)
Python Code:
def create_order(customers):
cust = fake.random_element(customers)
return {
"OrderID": fake.unique.random_int(min=100000, max=999999),
"CustomerID": cust["CustomerID"],
"OrderDate": fake.date_this_year(),
"Amount": round(fake.random_number(digits=4, fix_len=False), 2)
}
orders = [create_order(customers) for _ in range(100)]
df_orders = pd.DataFrame(orders)
print (df_orders)
Explanation:
- We store 20 fake customers, each with a unique CustomerID.
- Each order randomly selects a customer and uses their ID, simulating a relationship.
- The result is two tables with a foreign key relationship, perfect for BI and SQL tests.
- This approach is great for testing relational data scenarios.
Making Your Data Reproducible
When you want the same fake data every time (e.g., for testing), set a seed:
Faker.seed(123) fake = Faker()
Explanation:
- Setting a seed makes the random generation deterministic, so results never change between runs.
- It helps in testing, documentation, and training, as results are consistent.
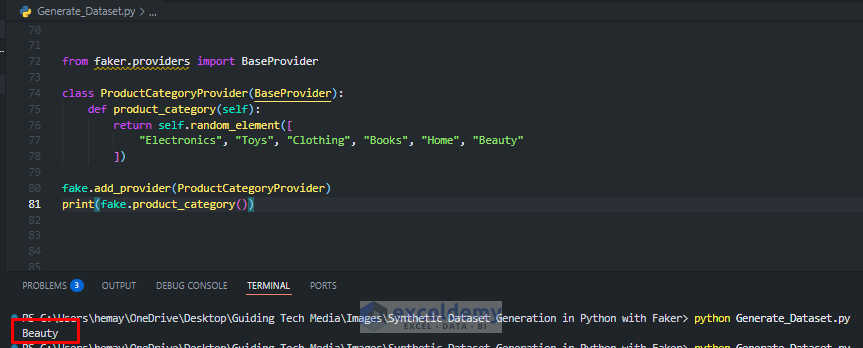
Extending Faker: Custom Providers
Suppose you need product categories (like for an e-commerce dataset), but Faker doesn’t have them built in. You can define your own custom providers for domain-specific data (e.g., product types, IoT devices, custom categories).
Python Code:
from faker.providers import BaseProvider
class ProductCategoryProvider(BaseProvider):
def product_category(self):
return self.random_element([
"Electronics", "Toys", "Clothing", "Books", "Home", "Beauty"
])
fake.add_provider(ProductCategoryProvider)
print(fake.product_category())
Explanation:
- You create a class inheriting from BaseProvider.
- Define your custom data method (e.g., product_category()).
- add_provider attaches it to your Faker instance.
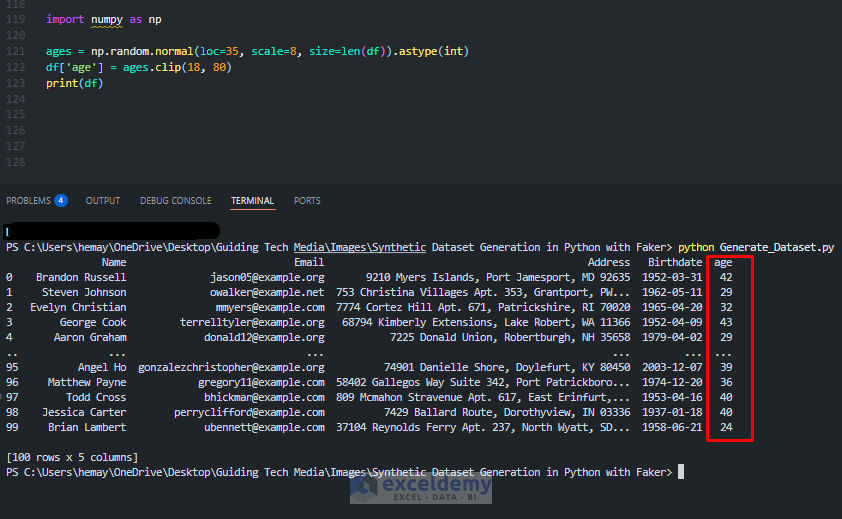
Faking Real-World Distributions
Simple random data may not reflect actual business data distributions (e.g., ages, order amounts, session durations). To create more realistic data, you can:
- Draw from distributions: Use numpy or random to generate columns like age, salary, and purchase amount.
- Stratify or bias fields: For instance, more users from certain countries or more frequent transaction dates.
Simulate user ages with a normal distribution:
import numpy as np ages = np.random.normal(loc=35, scale=8, size=len(df)).astype(int) df['age'] = ages.clip(18, 80) print(df)
Validating and Visualizing Synthetic Data
It is important to validate your dataset. To validate data:
- Compare summary statistics (mean, std, quantiles).
- Visualize with histograms, boxplots, and scatter plots.
- Check correlations and distributions.
import matplotlib.pyplot as plt
plt.hist(df['age'], bins=20)
plt.title('Age Distribution')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()
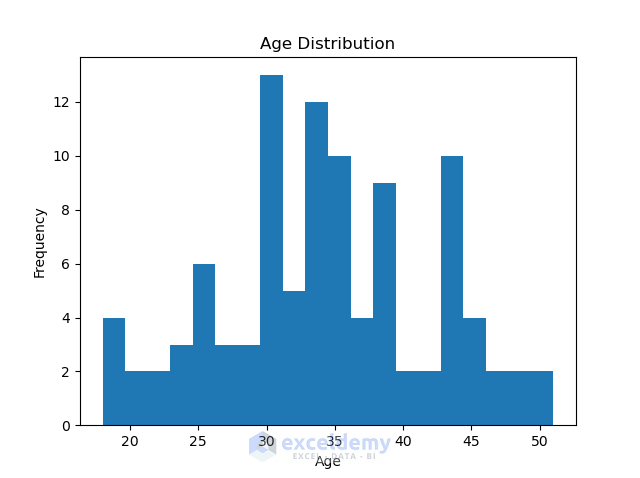
This step ensures your synthetic data is realistic and fit for its intended use.
Localization and Domain-Specific Data
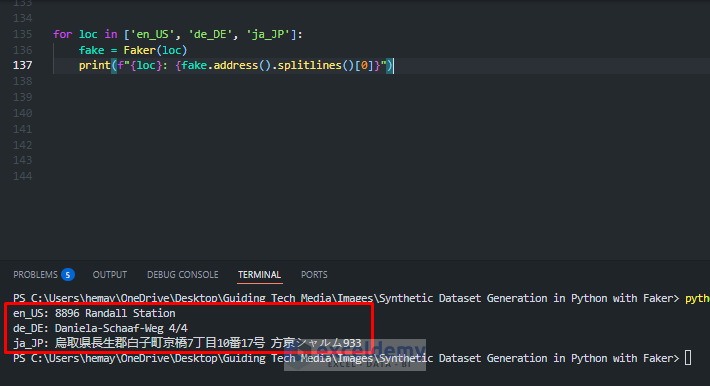
Faker supports over 40 locales. You can generate domain-specific data.
for loc in ['en_US', 'de_DE', 'ja_JP']:
fake = Faker(loc)
print(f"{loc}: {fake.address().splitlines()[0]}")
- Addresses, phone numbers, names, and more are localized.
- Great for internationalization testing.
Domain Examples: Healthcare, finance, e-commerce, add custom providers or distributions to reflect real-world domain patterns.
Where Can You Use Synthetic Data?
- Testing and development: Populate apps before you get real data.
- Analytics and dashboard demos: Show working dashboards with realistic, but not confidential, data.
- Teaching and workshops: Let students explore data hands-on without privacy risk.
- Prototyping: Build and tune algorithms before deploying real, sensitive data.
Best Practices: Privacy and Realism
- Don’t overfit: Synthetic data shouldn’t be so close to real data that it risks re-identification.
- Add noise: For high privacy, inject small randomness.
- Validate overlaps: Make sure synthetic data cannot be linked back to real data, especially if generated from small or sensitive sets.
- Use seeds for reproducibility.
- Export data to CSV for use in any tool.
- Extend with custom providers for special fields.
Conclusion
By following the tutorial, you can create realistic synthetic data using Faker in Python. It can easily generate high-quality, customizable, realistic synthetic datasets, tailored to your business case or tech stack. This lets you test, demo, or share analytics without worrying about data privacy or availability.
Get FREE Advanced Excel Exercises with Solutions!
